
 Newsletter
NewsletterHow to extract text content from image file by using A-PDF OCR?
Question
Solution
Don’t worry. We can help you settle the problem. A-PDF OCR is a fast and simple program that can OCR scanned PDF or scanned paper documents into text files. Also it supports OCR images in the format of gif, jpg, bmp and etc. Furthermore, it has a unique text editor that can help you edit the misspelled words. Besides, you are unnecessary to worry about the language in the reason that it supports more than 10 languages.
It is easy to learn and what you need to do is click the button to add the images and OCR them as Text, PDF or zip. With this fast OCR engine, you can own your PDF again in just a few minutes. If you are still in puzzle, the following tutorial will help you.
Step 1: Import images;

Step 2: Select the language and OCR range;

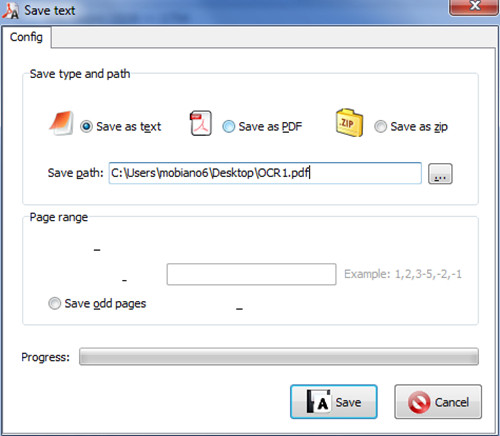
Step 3: Click the button “OCR and Save”, and choose the save type and path.
Related products
- A-PDF Watermark - Add image and text watermarks to a batch of Acrobat PDF documents
- A-PDF Label - Batch add formatted dynamic Label fields (mailing label) such as Name, Address, City to custom PDF templates (such as in form letters, on envelopes, business card, name badge and so on) for printing, The Label fields lists information come from a spreadsheet in MS Excel file
We always like improving our products based on your suggestions. Please send your feedback (or ask questions) to us in the contact page.
 Follow us
| Flip
HTML5 | Flip
Builder | Free
Office | Free Presentation Tool
Follow us
| Flip
HTML5 | Flip
Builder | Free
Office | Free Presentation Tool